Welcome to NXCALS documentation
(version: 1.3.13)
NXCALS is the new logging system based on Hadoop Big Data technologies using cluster computing power for the Data Analysis.
Quickstart
New to NXCALS? Check quickstart page.
NXCALS model
NXCALS accepts data from different data sources (systems) identified by their unique system identifiers. Each system keeps the time-based data for its entities in NXCALS system i.e. each entity has a state modelled by a set of properties with their values at a given moment in time. This information forms a record which is specific for each system and consist of:
- Fields identifying the entity
- Fields identifying the partition (a classifier used to physically put records in a disk folder and file)
- Fields identifying the timestamp
- Fields identifying the record version (optional)
Given set of all the record's fields is known in NXCALS as schema.
The entity record field set can also change in time. The state of the entity at a given moment is represented by the history of schema and partition changes, in short: entity history.
Records are physically split (grouped in different files on disk) by: system, partition (classifier), schema and date (which is split by day and in case of big files also by hour). It translates to the following location:
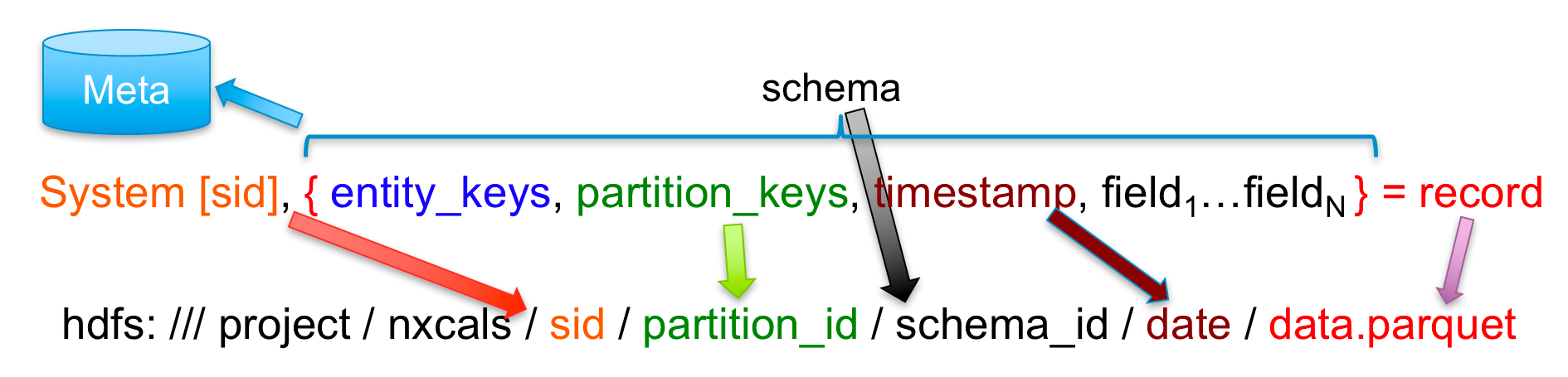
On top of the raw data there are high level variables defined that point to the particular field of the particular record type. The mapping between the high level variables and the raw record fields can change over time and the system remembers the history of the mapping changes.
The system allows to extract one or more fields from the stored records as raw data. It also allows to extract the high level variables data in the form of a record containing only one field.
System architecture overview
A simplified system architecture is presented in the diagram below. It shows flow of data from the stage when it is being acquired until the moment when it is made available to users.
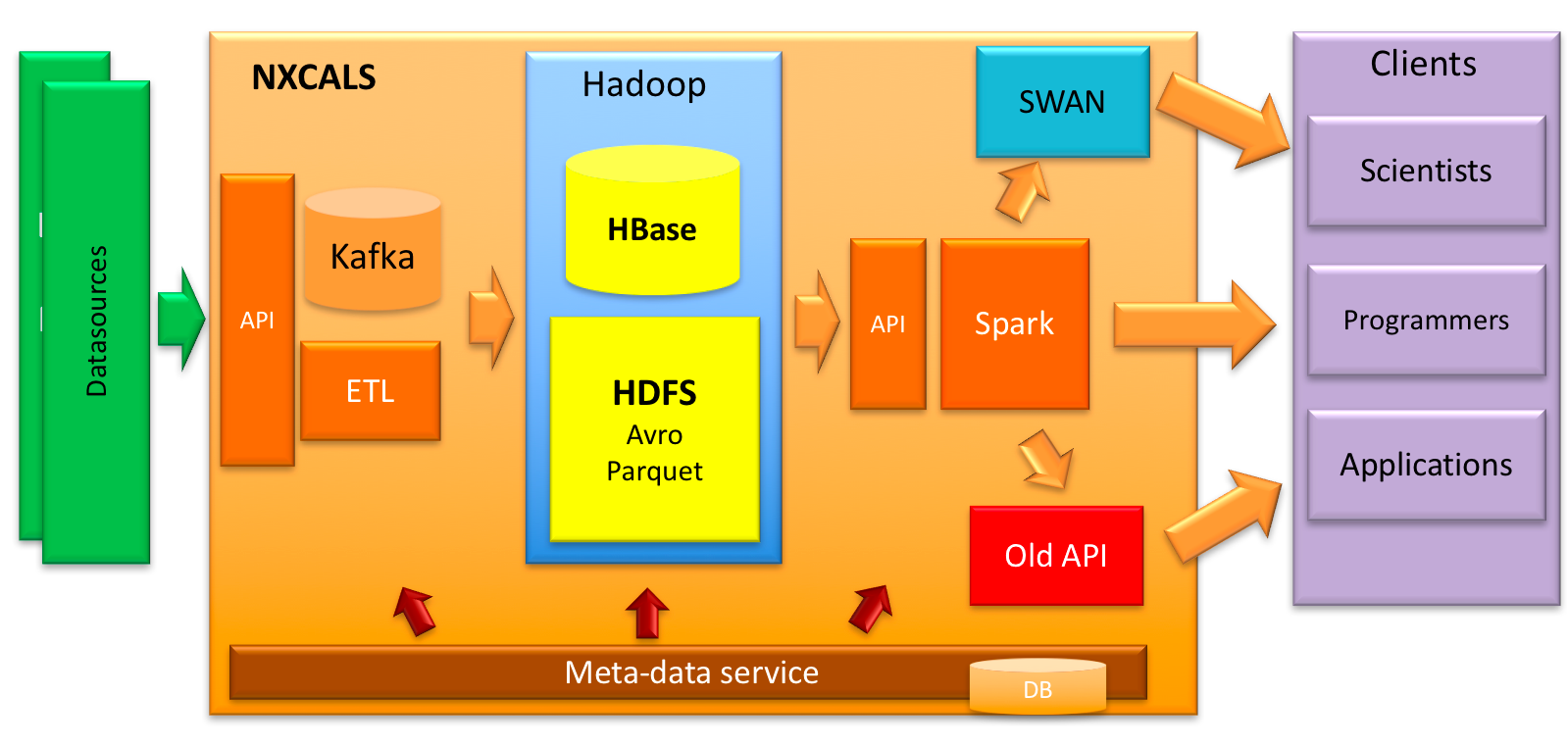
- Acquired data from different data sources is sent to NXCALS ingestion API.
- Then it is temporarily stored in Kafka which acts as intermediate persistent storage buffer for further processing. The current retention time is 2.5 days. In case of processing failures (infrastructure problems, bugs, etc.) this time period allows us to fix things and the data is not lost.
- From there it is collected by ETL process and being:
- sent to HBase and nearly immediately made available to users. Lifetime of recent data stored at this location is 48 hours.
- compacted, deduplicated and stored in HDFS (this process might be time consuming)
- At this stage, it can be acquired by NXCALS clients through Data Extraction API which "hides" origin of data (HBase or HDFS). Combined with Apache Spark it provides means of data extraction and analytics. It is made available in different interfaces including Web (through SWAN notebook), in NXCALS bundle (through Python API) or directly from Java API.
NXCALS meta-data (available through Meta-data service) is stored in the Oracle database.
NXCALS Data access
There are several possibilities for users to access NXCALS data using it's Public APIs: Extraction API, Backport API, Metadata API, CERN Extraction API and Extraction Thin API.
In this site we will explain and give examples of the functionality and the usage of those APIs. As we have built Data Access to serve as a Spark custom format, we can benefit using all the Spark APIs and supported languages.
Examples presented in the documentation feature various query builders that data-access API provides such as CMW specific query builders, as well as a dictionary-like ones, in order to achieve a more generic, system-agnostic approach.
In case of Extraction API data can be accessed through Java, Python 3 and Scala clients. It is easy to notice that the API in all cases is almost identical, in terms of functionality and syntax as explained on our Extraction API page.
Note
The easiest way to get started with accessing NXCALS data is to follow steps described in our Quickstart guide.
Dictionary
- Entity
- Entity is a representation of an object for which we store state changes over time. State is represented with a set of fields.
- Entity key definitions
- Set of field definitions uniquely identifying an entity. In case of CMW system:
{"name": "device", "type": "string"} {"name": "property", "type": "string"} - Entity History
- History of entity evolution, reflecting changes in its schema and partition.
- Partition
- A classifier allowing dividing data into some parts based on the values of the selected columns (partition keys) specified in the system definition.
- Partition key definitions
- Set of field definitions within a record uniquely identifying a partition. In case of CMW system:
{"name": "class", "type": "string"} {"name": "property", "type": "string"} - Record
- Set of grouped fields (keys definitions) of which some are required by system.
- Record version
- Records with the same version and timestamp are deduplicated in NXCALS. The version is there to allow clients to add data having the same timestamp twice with different values.
- Record version key definitions
- Optional set of field definitions within a record uniquely identifying a record version. In case of CMW system:
{"name": "__record_version__", "type": "long"} - Schema
- Set of all the record’s fields with their types. In NXCALS schema is dynamically discovered based on data.
- System
- A data source identified by its unique id. It is described by entity, partition, time and record version (optional) key definitions.
- Time key definitions
- Currently in NXCALS implemented as a single field of a type long uniquely identifying a timestamp. In case of CMW system:
{"name": "__record_timestamp__", "type": "long"} - Timestamp
- Data and time having a nanosecond precision in NXCALS
- Variable
- A pointer to a field or to the whole record (if no field is given in the config) characterized by name, description and unit.
- Variable config
- Mapping between entity and variable for a given time period.